AMD Zen 5架构深入揭秘!性能提升从何而来?- 解密AMD Zen 5性能提升的秘密
今天来跟大家聊聊AMD Zen 5架构。
在今年6月份台北电脑展上,AMD正式发布了基于新一代Zen 5架构的处理器产品,但当时公布的资料并不多,并未涉及到架构底层细节,也缺乏和Zen 4架构的全面对比。

在近日的Hot Chips大会上,AMD深入展示了其全新的Zen 5核心架构,包括各个微架构模块的具体变化,涉及桌面端、移动端、服务器端异同,包括Zen5、Zen5c的新理念以及升级的RDNA 3.5 GPU、XDNA 2 NPU等信息。
今天我们就来详细看一下Zen 5架构有何独特之处。
▉ 01 架构升级的让CPU性能突飞猛进
我们都知道,处理器的架构设计格外重要,每一次的架构升级都能给处理器性能带来极大的提升。AMD正是凭借Zen架构的出现才扭转了当年被逼的节节败退的局面。
CPU架构设计是一个极为复杂的工程,哪怕是个升级版本。人们往往意识不到CPU架构设计有多难。

我这里打个比喻:把CPU的架构比作是一座楼房,砖瓦油漆等建筑材料就相当于CPU的组成材料。架构的意义就在于把所有的建筑材料按一定的规则、最优化的布局顺序排列组合,形成一座楼房。X86架构就是楼房的一种,其他分支架构就如同楼房的种类一样,类似于普通民房、别墅、摩天大楼等等,因为采用了不同的建筑材料和建筑方式所以各有侧重。
拿这次AMD发布的Zen 5架构的CPU举例来说,新架构的应用就相当于建筑材料的品质提升。如采用了更坚固的钢筋混凝土和更快速的电梯,更轻薄的三合板,更节能的灯泡以及更环保的涂料等等,使建筑的档次得到根本性的提升,加强建筑物的耐用性、舒适性以及环保等性质,转换到CPU来看就是更强劲的性能、更好的使用体验,更低的功耗。
总的来说,架构的升级代表了CPU性能的得到提升,功耗降低。我们常说的制程其实也包含在架构之中了,同时期同一架构的CPU采用的制程是一样的,应该说制程只是新架构的一个部分(英特尔有在几乎同时期不更新架构,只进行小的优化,同时提升工艺制程的发展策略,简称Tick-Tock模式)。同时,架构还能区分CPU的类型,用于衡量CPU的性能提升,是CPU的重要指标之一。
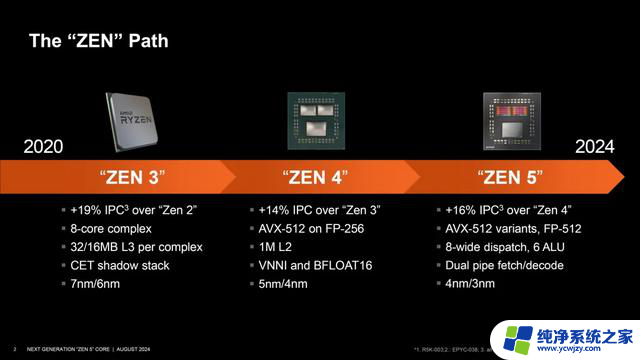
AMD 的Zen 1核心架构于2017年首次推出,由于架构的升级,相比于上一代架构推土机 IPC大幅提升52%,远超当初设定的40%目标,这在整个微处理器历史上都是极为罕见的进步。
Zen架构的发布取得了各种好评,也是从那时起,AMD对Zen架构不断深入打磨,如今已经推出了五种新架构(Zen+, Zen 2, Zen 3, Zen 4, Zen 5)。每次架构的变革都带来性能大幅度的提升,包括增加每时钟周期指令数、拓展指令分派与执行带宽、翻倍缓存数据带宽、AI加速等等。
▉ 02 Zen 5架构做了哪些升级?
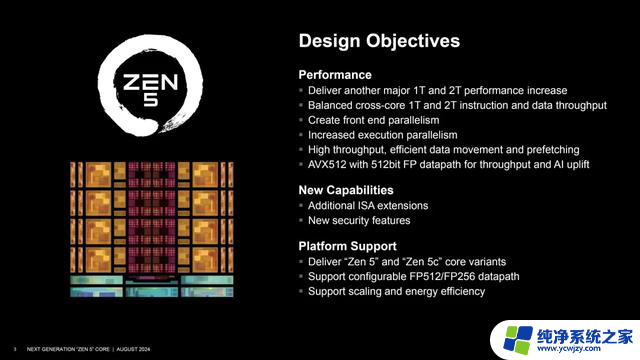
做任何工作的时候都要有一个目标,AMD在CPU架构设计时当然也是如此。我们先来看看下图中Zen 5架构设计时的目标。
其实,现代CPU架构都有着成熟的体系,除非出现完全颠覆性的计算体系,CPU架构设计师要做的,就是根据预设目标,确定不同单元模块的规格规模,然后有机地组合为一个整体,发挥出最大效率,既不能造成浪费,也不能出现瓶颈。
目前CPU架构整体可分为前端、后端两大部分,细分包括指令预取与解码、整数执行、浮点执行、载入存储、缓存等不同单元模块。
Zen 5的整体思路就是适当放大规模,很多地方甚至翻番,比如前端部分改成了双预取、双解码流水线,可以更高效地处理各种负载,打个比方就是源头水闸更开放,能释放的水流量更足。

同时,在分支预测方面,AMD Zen 5也做了极大提升,吞吐量更大,精度更高,延迟更低,而且指令缓存的延迟和带宽同样得到了提升,就像是水渠也更宽敞了,面对更多的水流不会出现溢出情况。
因此,Zen 5的目标就很简单,核心就是继续大幅提升单核、双核性能,为未来奠定新的基础,同时实现满血版AVX-512,支持可配置的256/512位浮点数据路径,有助于大大提升AI能力。
另外,在浮点与矢量执行单元部分,最核心变化就是在Zen 4架构引入AVX-512指令集的基础上,从仅支持256位数据宽度强化为支持完整的512位。令人唏嘘的是,由于Intel 12代酷睿开始采用异构混合架构,其中E核不支持AVX-512,Intel当年的独门武器,如今反而成了AMD的独家秘笈。

Zen 5还有一个重要使命就是进一步普及紧凑版核心,也就是Zen 5c,包括移动端和服务器端。上一代其实就有了Zen 4、Zen 4c,并在数据中心端大放异彩,而在移动端只是非常低调地小试牛刀,这次相信尝到甜头的AMD要大面积推广普及。
另外的更新就是更灵活、更高的能效,4/3nm工艺支持,ISA指令集增强,这也是Zen 5的主要目标。
▉ 03 我们来看看具体的细节升级
首先我们来看下Zen 5的微架构总览,从前端到后端,从整数到浮点,从缓存到带宽,AMD都进行了全面升级,下面我们一一来讲述。
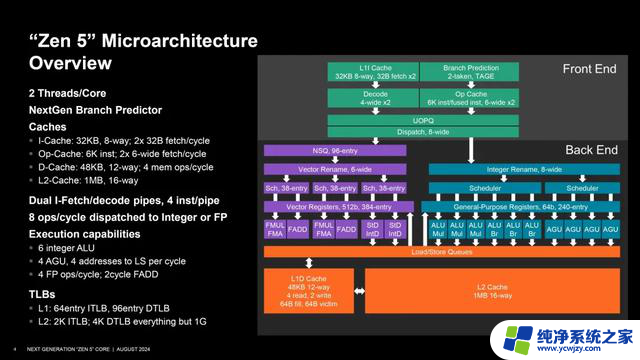
首先,我们先来看下缓存部分,这部分是大家经常见到也比较容易理解的。Zen 5一级指令缓存容量并没有变化,还是32KB,8路关联,每时钟周期两组32B拾取;数据缓存容量则是增至48KB,12路关联,每时钟周期4个内存操作。
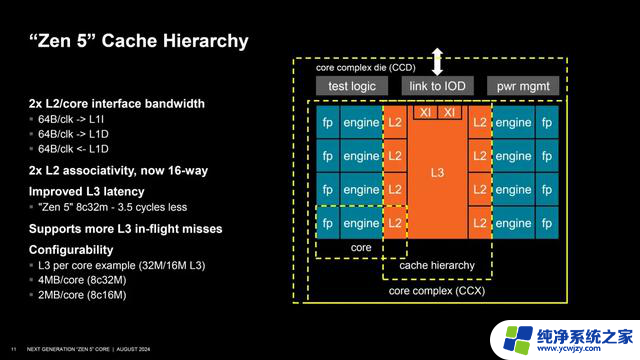
上面是Zen 5 CCX模块的核心与缓存体系结构图。另外,操作缓存(Op-Cache)如今能够支持6个指令,每时钟周期支持两组6个宽度的拾取。另外,就是二级缓存容量还是1MB,16路关联,这个变化不大。
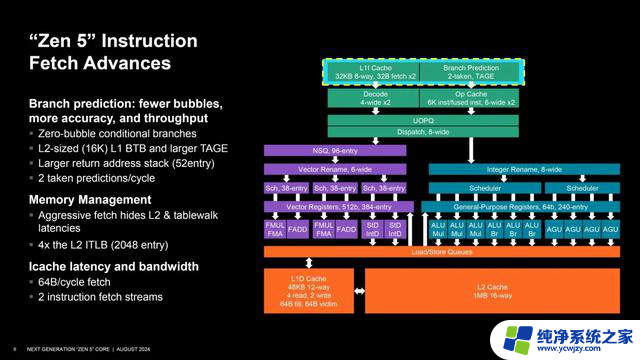
在分支预测与拾取部分,AMD Zen 5也做了极大的优化提升,例如支持“零泡沫”(zero-bubble)的条件分支,这意味着分支预测器在访问BTB(分支目标缓冲)时无需付出任何代价;同时,L1、L2 的BTB也提升了容量,从之前的1.5K/7K来到16K/8K)和精度,并增大了TAGE,这对有条件的间接分支都很关键。
另外,每时钟周期拾取和解码指令数从32B翻番到64B,返回寻址堆栈从32个变为52个,每时钟周期支持最多3个预测窗口,指令缓存的延迟和带宽也都有所改善。
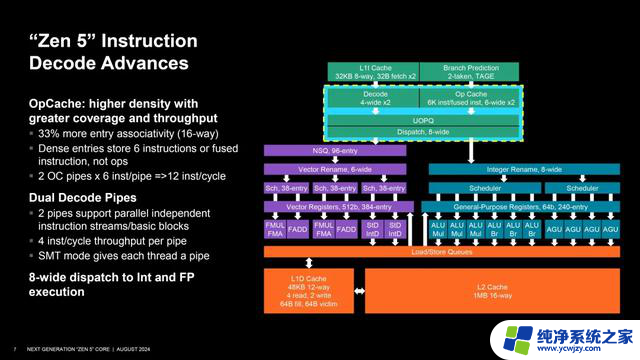
在新的指令解码系统方面,AMD Zen 5配备了双解码流水线,可以独立并行处理指令流,每条每时钟周期4条指令;操作缓存(OpCache)关联路数增加1/3达到了16路,可存储最多6条指令,配合双流水线,每时钟周期就是12条指令。
在开启SMT多线程的时候,每个线程都是一条流水线;另外关键的是,通往整数和浮点单元的分派队列宽度从6个增至8个宏操作(macro-op),并支持操作的融合,可以让来自某些指令的两个宏操作作为一个来处理。
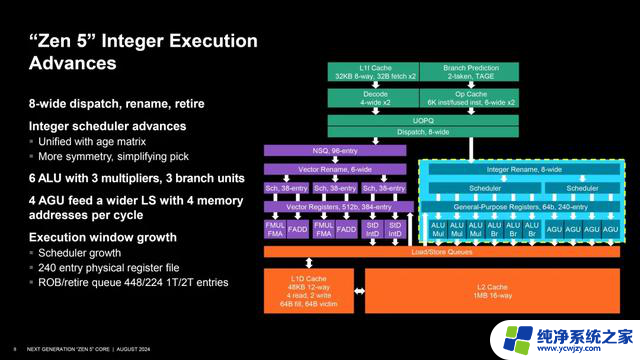
接下来是整数单元本,这也是Zen架构的强项,现在更加“膨胀”,分派、重命名、引退达到了8个宽度;ALU整数逻辑单元从4个增加到6个,包括3个乘法单元和3个分支单元,ALU调度器也从24个大幅增加到88个。
AGU地址生成单元从3个增至4个,每时钟周期可执行4次内存寻址,AGU调度器从48个独立、24个与ALU共享变为独立的56个。可以说,整数单元的大大强化,是锐龙9000系列在加速频率微增或不动、基准频率降低情况下取得性能大幅提升的关键所在。
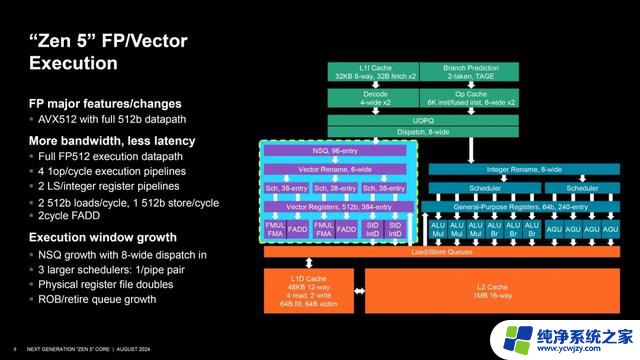
在矢量和浮点能力也显著增强,尤其是AVX-512指令集终于可以支持完整的512位数据路径,同时保留256位,非常灵活,可以兼顾高性能、高效率,也不至于让功耗失控。
整个浮点执行单元的带宽和延迟都做了升级,包括4条浮点执行流水线(Zen4 3条)、3×38个浮点调度器(Zen4 2×32个)、2条载入存储与整数寄存器流水线、每时钟周期2个512位载入和1个512位存储、双循环FADD等等。
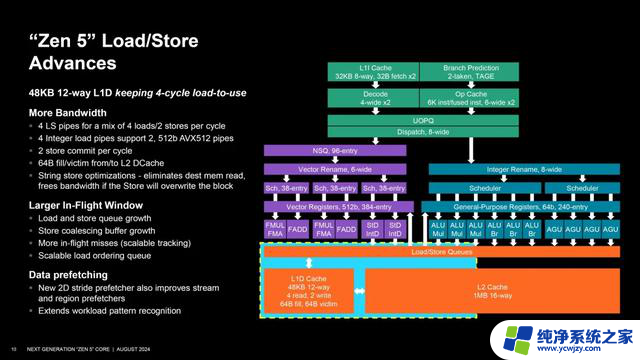
一二级缓存部分的数据带宽全面扩充,尤其是一级数据缓存来到了12路48KB,4条载入/存储流水线每时钟周期可以执行4个载入(Zen 4还是3个)和2个存储,4条整数载入流水线可以合并为2条;外还全面涉及TLB、实时窗口、数据预取等等部分。

指令新增加的不算很多,AVX-512仍是重点,包括拓展至VEX编码的VNNI/VEX、矢量配对为一对掩码寄存器的VP2INTERSECT[DQ];另外就是PMC虚拟化,可为客户机提供更好的安全保障,以及异构拓扑,显然是为Zen 5、Zen 5c的组合准备的。
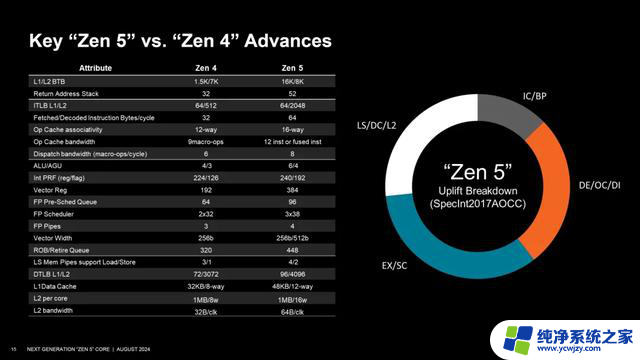
下面我们来看下Zen 5与Zen 4技术规格细节对比,也是对上边所讲的一个概括。
我们注意所有列出的参数都变了,从前端到执行单元到缓存,因此可以说Zen 5是一次全面性的架构翻新,是对架构的一次“大改”,这才有了频率下来了但性能上去了的神奇结果。
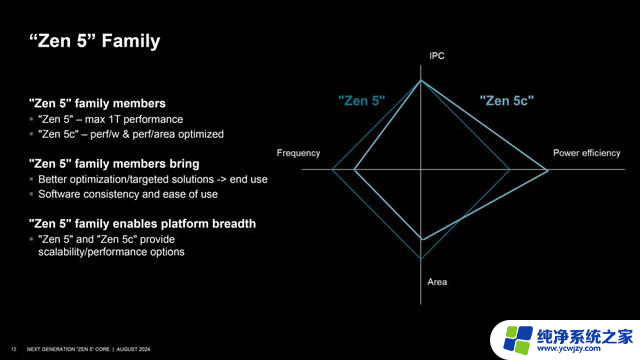
我们来看下Zen 5、Zen 5c的区别,二者架构设计、IPC性能、ISA指令集都是完全相同的,也都支持多线程,对于操作系统和应用软件而言是透明和等价的,基本上不需要特别考虑调度问题,这和Intel的异构大小核天然不同。
Zen 5的追求是尽可能高的单核频率与单核性能,还有足够大的三级缓存。Zen 5c则降低了频率,提高了能效,同时精简了部分三级缓存。

Zen 5架构在桌面台式机、移动笔记本、服务器数据中心三大领域采取了不同的产品设计和实现方式,都非常有针对性。
桌面上,经典chiplet设计,一个或两个CCD(等同于CCX),外加完全延续上代设计的IOD,架构上是纯粹的Zen 5,不会用Zen 5c;笔记本上,继续单芯片,双CCX组合成一个CCD。全部是Zen 5、Zen 5c的组合,最多分别4个、8个;服务器上(包括嵌入式),设计更加灵活,CCX有的更大有的更小,Zen 5、Zen 5c都会有,但应该会和Zen 4、Zen 4c一样发展各自的产品线,不会混合使用。
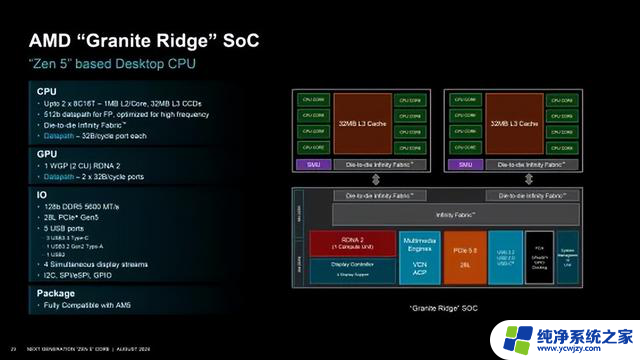
代号Granite Ridge的桌面版锐龙9000系列的裸片、核心布局图。和之前基本一致,每一组CCX/CCD里有8个核心、8MB二级缓存、32MB三级缓存,但注意两种CCX/CCD是不互通的,所以哪怕12/16核心型号有64MB三级缓存,但每个核心最多也只能访问自己所在CCX/CCD里的32MB。
当然,理论上可以通过IF总线跨越访问,但是带宽太低、延迟太高,没法用。IOD部分和锐龙7000系列上是一样的,因此同样有2个RDNA2架构的GPU CPU单元、128位双通道DDR5-5600内存控制器、28条PCIe 5.0总线、5个USB接口、四组显示输出。
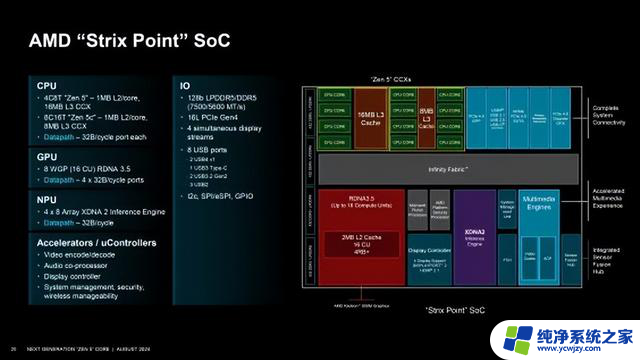
代号Strix Point的移动版锐龙AI 300系列的裸片、核心布局图。变化还是挺大的,上一代Zen 4、Zen 4c组合只在两款低端型号上低调尝试,这次变成了标准的Zen 5、Zen 5c组合。
注意看左上角,分了两个黄色框图,4个Zen 5核心和对应的16MB三级缓存是一组,8个Zen 5c核心和对应的8MB是另一组,也就是和桌面上类似甚至更极端,Zen 5、Zen 5c三级缓存各用各的,没法互通,24MB也只是个总容量。
GPU部分是RDNA 3.5架构,8组WGP也就是16个CU,1024个流处理器。NPU部分是48阵列的XDNA 2架构。这俩大家都很熟悉了。IO部分,支持128位LPDDR5X-7500/DDR5-5600内存、16条PCIe 4.0、8个USB接口,包括两个USB4。
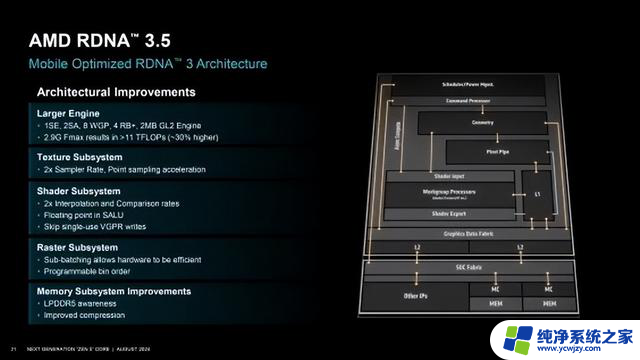
与上一代GPU相比,RDNA 3.5的纹理渲染率达到了2倍,并且显存带宽也将有所增加。具体到实际表现上,与Hawk Point处理器相比,TimeSpy性能提升32%,而Night Raid提升19%,这还是在15W条件下的使用场景,如果TDP提升至25W或者35W,那么GPU性能将会提升更大。在台北电脑展上AMD就已经公布了一部分的测试成绩,应对1080P分辨率的游戏也是完全没有任何的问题。
当然规模也跟着增大了,12个CU变16个CU,4个渲染后端(RB+),最高频率提升到2.9GHz,理论性能提升了大约30%,只是由于驱动还不到位,目前在游戏性能上还没有完全释放出来。
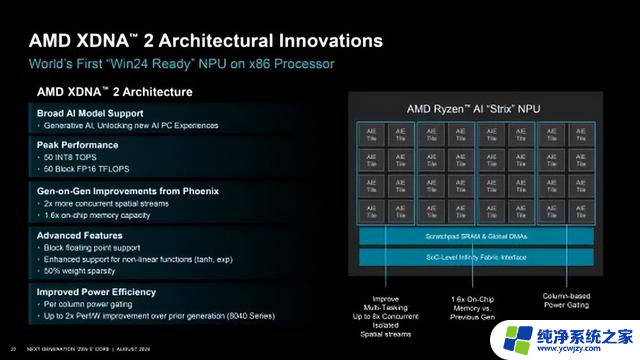
XDNA 2架构的NPU AI引擎,号称第一个为“Windows 24”做好准备的x86处理器NPU,不过现在能用到NPU的应用还是太少了,无论AMD还是Intel,最新的AI PC更多的还是概念。
AMD表示对于AI应用来说,不同应用的模型大小实际上有着很大的不同。比如说实现实时应用的AI特效所使用的模型就十分小巧,不需要太大的AI算力,但是像是Stable Diffusion 或者是LLM,就需要更大的AI算力,甚至还需要GPU来帮忙,但是GPU的功耗十分高。如果以能效比计算,GPU是CPU的8倍,而NPU则是CPU的35倍,因此越来越多的厂商将NPU植入到处理器之中。而AMD也是世界上首个将NPU植入到X86处理器中的厂商,也初步打造了属于自己的AI生态系统。

总的来说,Zen 5作为一次大规模的架构升级,从目前表现来看是相当成功的,无论笔记本上的锐龙AI 300系列,还是桌面上的锐龙9000系列,性能、能效都提升巨大、可圈可点,服务器上的第五代EPYC同样值得期待。
就算你看不明白那么多专业术语,光是从图上也能看到Zen 5对于处理器架构的各个部分都进行了升级,所有这些升级都是以提升IPC和执行效率为目标,这也意味着就算频率不变,Zen 5的性能也会高出上代不少。
随着Intel即将推出的的Arrow Lake上市,错失一代之后如今Intel终于回归高性能之争,对于深陷泥潭的英特尔来说,一定会加大市场上的宣传,相信市场上又一场好戏开始了!
END