微软推出XOT方法,提升语言模型推理能力,引领语言技术发展潮流
更新时间:2023-11-15 14:36:44作者:ycwjzy
11 月 15 日消息,微软近日推出了名为“Everything of Thought”(XOT)的方法,灵感来自谷歌 DeepMind 的 AlphaZero,利用紧凑的神经网络,来增强 AI 模型推理能力。
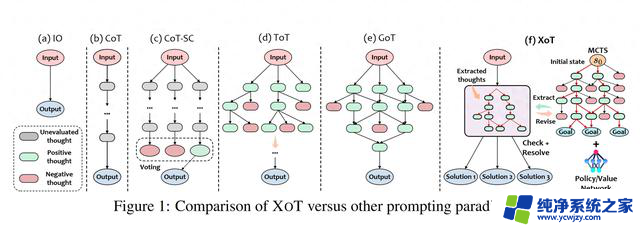
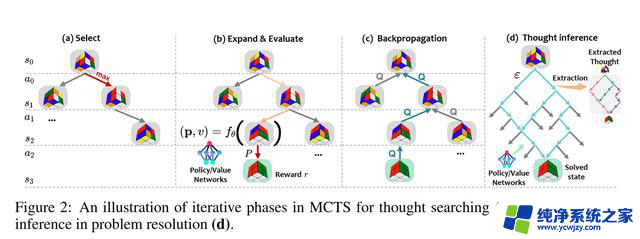
微软和佐治亚理工学院、华东师范大学合作开发了该算法,整合了强化学习(reinforcement learning)和蒙特卡洛树搜索 (MCTS) 能力,在复杂决策环境中,进一步提高解决问题的有效性。
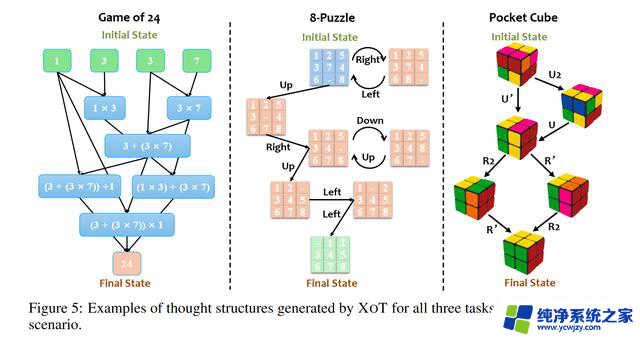
注:微软研究团队表示 XOT 方法可以让语言模型扩展到不熟悉的问题上,在 Game of 24、8-Puzzle 和 Pocket Cube 严苛测试中提升明显。结果表明,XOT 明显优于其他方法,甚至解决了其他方法失败的问题。但是,XOT 并没有达到 100% 的可靠性。
XOT 框架包括以下关键步骤:
预训练阶段:MCTS 模块在特定任务上进行预训练,以学习有关有效思维搜索的领域知识。轻量级策略和价值网络指导搜索。思想搜索: 在推理过程中,预训练的 MCTS 模块使用策略 / 价值网络来有效地探索和生成 LLM 的思想轨迹。
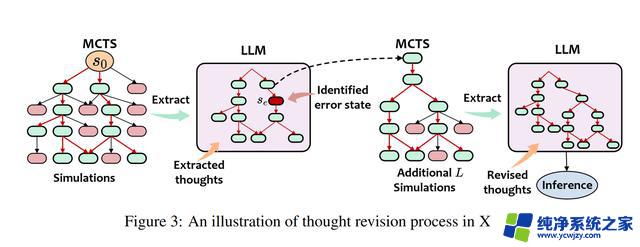
思想修正:LLM 审查 MCTS 的思想并识别任何错误。修正的想法是通过额外的 MCTS 模拟产生的。
LLM 推理: 将修改后的想法提供给 LLM 解决问题的最终提示。
在此附上论文 [PDF] 地址,感兴趣的用户可以深入阅读。