微软发布位置工程,提升RAG与上下文学习效果
提示工程通过添加、替换或删除段落和句子改变提示,调整语义信息,激发LLMs的推理能力。比如CoT通过在问题的结尾附加“Let's think step by step”这几个词,鼓励模型生成推理过程。
GPT-3.5研究测试:
yeschat
GPT-4研究测试:
Hello, GPT4!
Claude-3研究测试(全面吊打GPT-4):
AskManyAI
而微软这篇工作发现在tokens之间引入占位符token可改变其他token的相对位置。这些占位符token不参与注意力分数的计算,但占据了token索引位置。因此可能优化提示中不同段落之间的注意力权重。
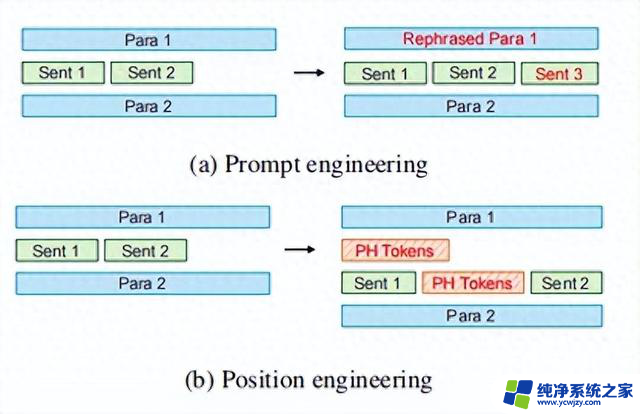
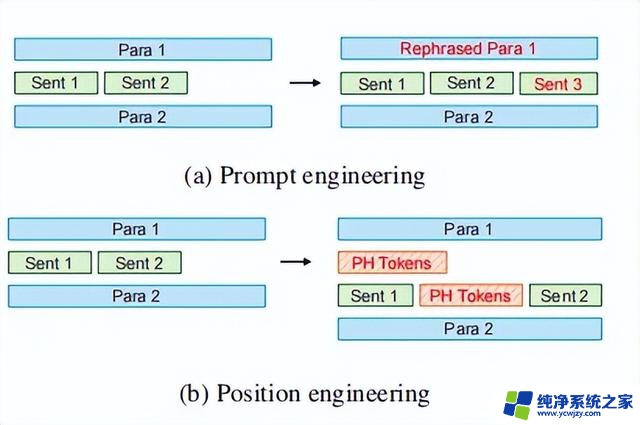
▲提示工程与位置工程的比较。"Para"指的是提 示中的段落,"Sent"指的是句子。
通过在两个广泛使用的LLM场景中——检索增强生成(RAG)和上下文学习(ICL)——对位置工程进行了评估。结果表明,位置工程在两种情况下都显著优于基础模型。
又一充分激发LLMs能力的新策略出现啦,说不定也是一个产出论文的好方向!
论文标题:
Position Engineering: Boosting Large Language Models through Positional Information Manipulation
论文链接:
https://arxiv.org/pdf/2404.11216.pdf
为什么改变token的位置有奇效,先来了解一下LLMs如何整合位置信息。
前置知识令表示输入到语言模型的tokens,用表示相应的token嵌入。首先,注意力层计算(查询)、(键)和(值):
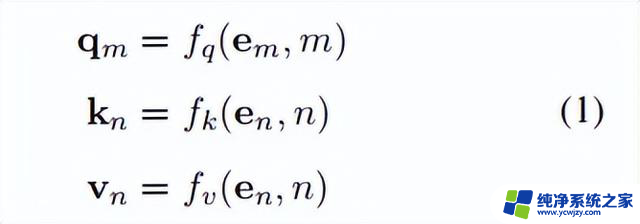
其中, 和 分别是token的位置索引。自注意力计算如下:
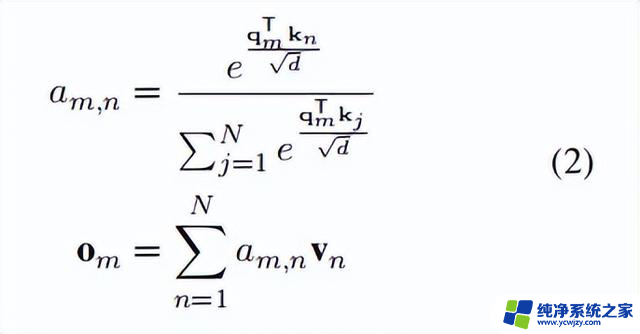
其中, 是一个标量,表示查询中第个toekn与值和键集中第个token之间的注意力分数。表示注意力层的维度,而表示第个查询token的输出。
然后通过引入与和相关的位嵌入向量引入绝对定位:
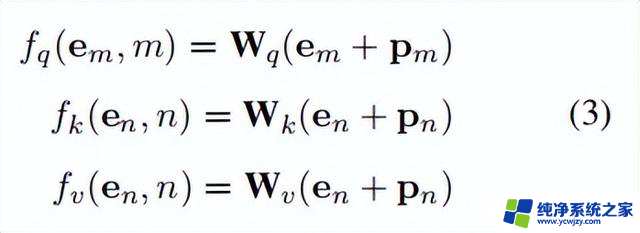
位置嵌入的第和维度的计算方法如下:
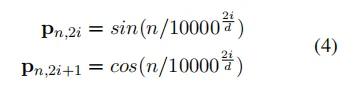
而近期的大模型如Llama和Mistral多采用RoPE(Relative Position Embedding),一种相对位置嵌入。它利用一个特定设计的矩阵(维度为d × d,参数化为i),对查询和键向量进行如下修改:
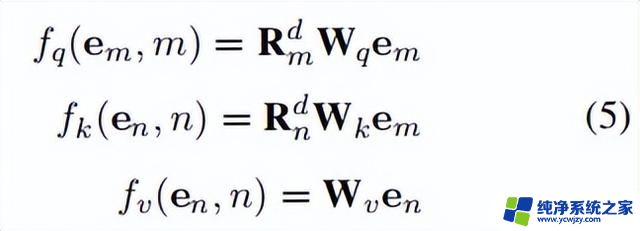
矩阵 有一个独特性质,即,这导致:
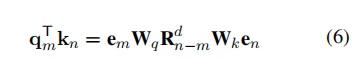
因此, 在公式(2)中, 模型只关注相对位置, 而不是绝对位置和。
位置工程本文所提到的位置工程仅对公式(1)中使用的位置信息进行调整。目标是找到一个位置编辑函数,改变并融入模型中的token位置信息,提升LLM的表现:
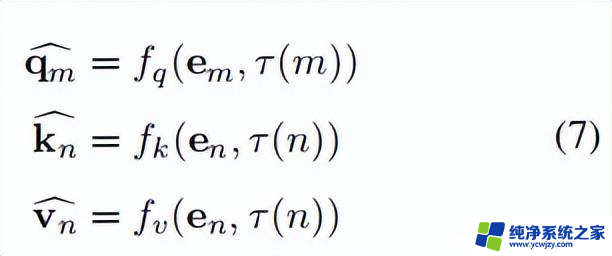
其中ττ。确保(1)两个不同的token不会被赋予相同的新的位置索引;(2) 语言建模中的因果关系保持不变,只有索引更大的查询向量可以访问索引相等或更小的键和值向量,反之则不行。
具体来说在需要改变位置关系的token之间插入位置占位符,定义为θθθ,比如在RAG任务重θ表示在指令和文档段之间插入θ个占位符token,而θ则表示在文档段和问题之间插入占位符token。
占位符token不参与注意力分数计算,但分配了位置索引。当按照公式(2)中的描述计算,并且第或个 token被识别为占位符时,常规计算会被跳过,被设置为 0。
如图下图b所示,将占位符token插入句子1和2之间影响了它们之间的相对位置信息,进而影响两个句子中tokens之间的注意力分数计算。
 实验
实验作者在LLMs两大流行任务检索增强生成(RAG)和上下文学习(ICL)上评估了位置工程的有效性,主要测试模型为是Llama-13B-chat。
1. RAG的位置工程RAG方法首先涉及与用户查询相关的文档检索。随后,检索到的内容被提供给生成模型,以形成响应。
数据集作者使用了四个开放域问答数据集:NQ open、EntityQuestions、TrivialQA和WebQuestions。从每个数据集的原始训练集中随机选取了300个问答对构建位置工程训练集。同时,从它们的原始测试集中随机选取了2,000对作为测试集;若某个数据集没有测试集,则使用其评估集替代。
检索模型:采用了经过MS-MARCO数据集微调的Contriever模型。检索源来自维基百科,每个文档段落限制为100个词。检索了k个文档段落,其中k分别取值为1、3、5,并将这些段落连接起来后输入到LLMs中。
评估指标:采用了最佳精确匹配准确率,即判断输出中是否包含正确答案。
搜索空间RAG的提示输入分为三个部分:指令、检索到的文档与问题。

通过在指令和文档段之间插入θ 临时占位符token,以及在文档和问题段之间插入 θ临时占位符 token。如下图所示:
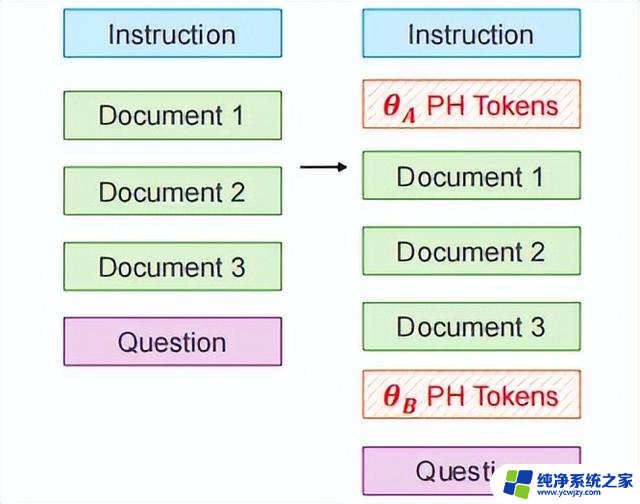
为了缩小搜索空间,限定 θ 和 θ 的值在预定义集合{0, 100, ..., 2500} 内。同时,由于上下文窗口大小的限制,要求 θθ。
作者在 Llama-13B-chat 模型的训练集上评估所有组合的性能,然后将最佳配置应用到测试集。结果如下表所示:
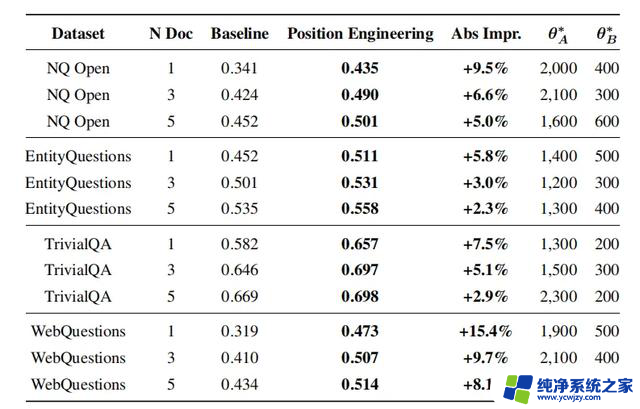
结果表明,位置工程显著提升了RAG在所有设置下的性能。其中,在WebQuestions数据集中,仅使用一个检索到的文档时,性能提升最为显著,达到了15.4%。
θ和θ在所有考察的数据集中的最佳参数都表现出一致的趋势:
θ 通常取值在1,000到2,000的较大范围内,而 θ则是一个相对较小的数值,其范围大致在200到600之间。这些参数设置对于优化RAG的性能起到了关键作用。
2. RAG通用位置工程设置探索作者还探讨了在“确定一个单一的位置设置“的情况下,能否普遍提升RAG在不同数据集和各种检索文档数量下的性能。
作者可视化了每个位置配置θθ的平均百分位值,如下图所示。这些值首先通过聚合给定数据集和特定检索文档数量的全部准确率得分得到,然后计算百分位分并对所有配置进行平均。
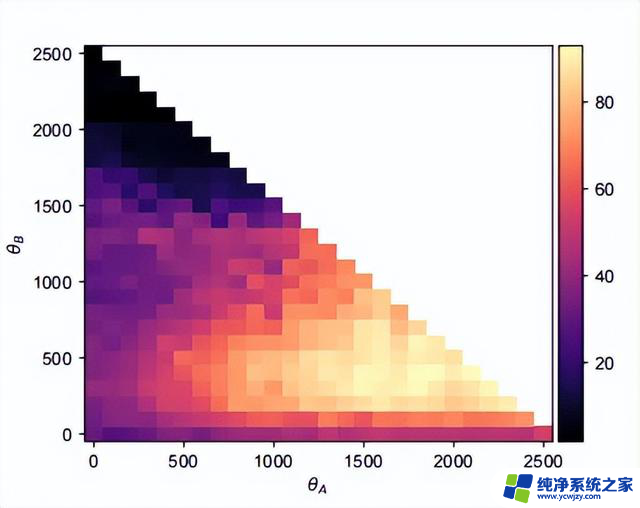
基线配置θθ的平均百分位数为31.6。大约68%的配置可以通过简单地调整位置信息来超过基准性能。
通常,在1300到2000的范围内选择θ值,并将θ设置在300到500的范围内是有利的。将θ设置为过高的数值(例如超过1500)会显著降低性能,可能是因为它导致忽略提示中的文档信息。此外,固定θ值,增加θ通常性能会更好。
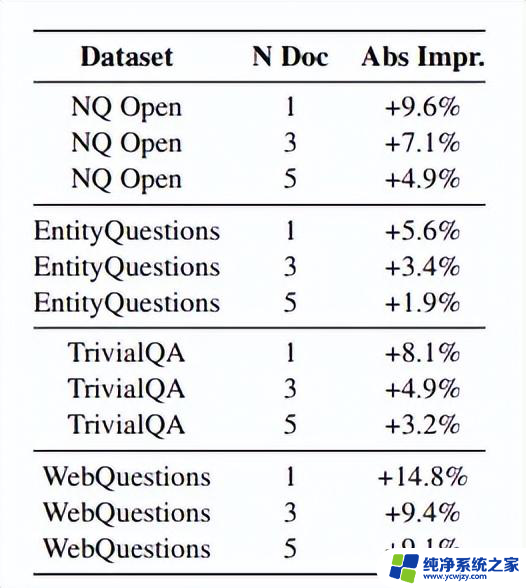
在训练集上,θ,θ表现出最高的百分位值为92.9。将这个配置应用于所有数据集和检索文档数量的测试集。如下表所示,相比基线,性能都有所提高。
 3. 移除指令段探索
3. 移除指令段探索从上节的实验结果可以看出,为了达到最佳性能,偏好较大的θ。θ表示指令段和文档段之间的间隔。较大的θ减少了指令段的影响。这引出了一个问题:完全移除指令段是否会进一步提升性能?结果如下表所示:
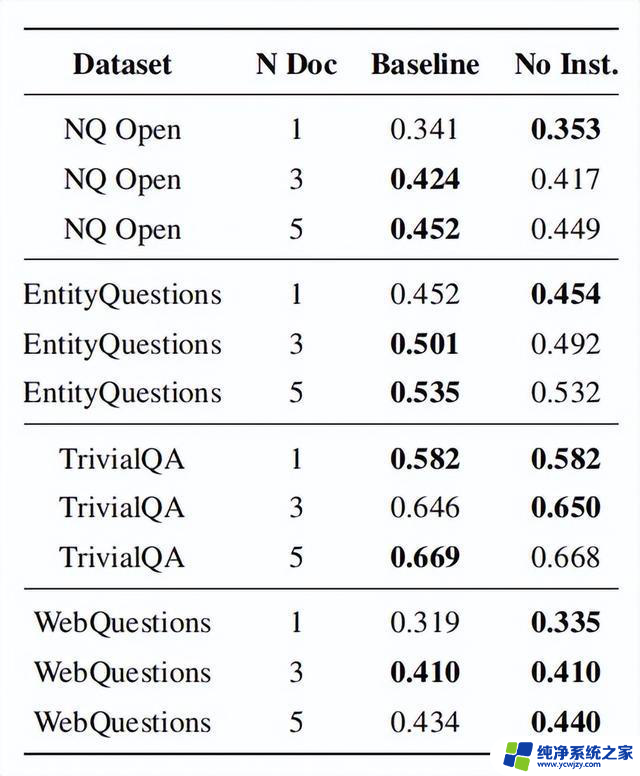
移除指令段的性能与基线设置相当。在使用一个检索到的文档时,WebQuestions 数据集上的最大提升达到了 2%。然而,同一体验设置下的位置工程改进幅度为 15.4%。
因此,为了实现最佳性能,我们的策略应当是削弱指令段的影响,而非完全消除它。对于位置工程而言,这相对容易实现。但对于提示工程来说,这却是一个挑战。
4. ICL的位置工程在上下文学习(ICL)中,LLMs通过观察多个上下文示例来学习新任务的能力。
数据集作者选用TREC和SST2两个数据集。主要关注TREC数据集中6个粗分类问题,SST2数据集包含电影评论,目标是将其分类为正面或负面。训练集从TREC和SST2的原始训练集中随机选择300个样本。测试集使用TREC的全部500个 样本测试集。SST2数据集使用其验证集的全部842个样本作为测试集。
对每个测试样本,从训练集中每个类别随机选择3个示例作为上下文 示例,TREC为18个,SST2为6个。采用精确匹配分数作为评估指标。
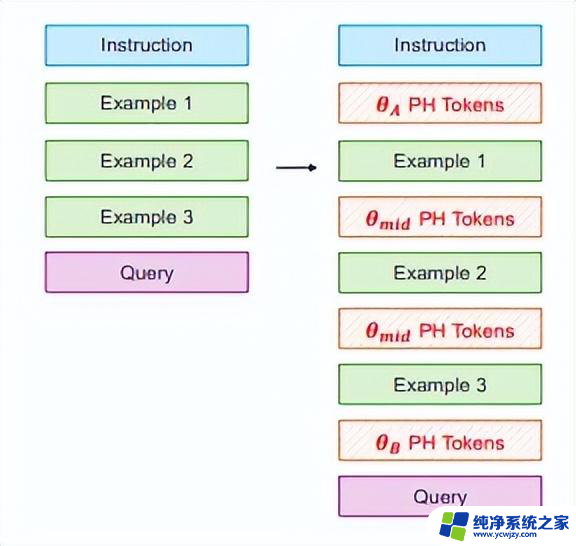
搜索空间提示模板如下图所示,分为三个部分指令段、 示例段和查询段。对于TREC数据集,使用类似的提示模板。仅将"Review"替换为"Question","Sentiment"替换为"Question Type",

作者在指令段和示例段之间插入了θ占位符,在示例段和查询段之间插入了θ占位符,以及在示例之间插入了θ占位符,如下图所示:
在实验过程中,为θ和θ的候选值设置了集合{0, 100, ..., 600},尝试从0到600的多个不同间隔,以找出最佳的位置配置。对于θ,设定了值集{0, 20, ..., 100},以探索示例之间的最佳间隔。结果如下表所示:
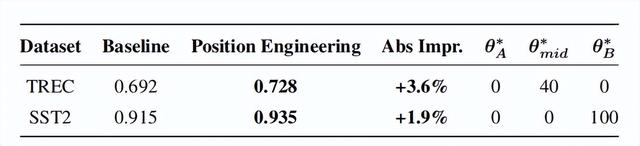 在两个数据集上都实现了性能提升,TREC 数据集上的绝对提升为 3.6%,SST2 数据集上的绝对提升为 1.9%。最优的位置θθθ在不同的数据集之间有所变化。TREC 需要将 θ 调整为 40,同时设置θ 和 θ 为 0;而对于 SST2,最优设置是将θ 设置为 100,同时 θ 和 θ 保持为 0。当θ值设置在{200, 300, ..., 600}范围时,模型性能明显下降,这与RAG任务中的观察结果相吻合。θ主要调节示例段对模型的影响。对于SST2任务(即对评论情感进行分类),由于LLM可能已具备相关基础知识,选择θ可以适度降低示例段的影响。而对于TREC任务(需LLM从示例中学习问题类型),保持θ则更为合适。结论
在两个数据集上都实现了性能提升,TREC 数据集上的绝对提升为 3.6%,SST2 数据集上的绝对提升为 1.9%。最优的位置θθθ在不同的数据集之间有所变化。TREC 需要将 θ 调整为 40,同时设置θ 和 θ 为 0;而对于 SST2,最优设置是将θ 设置为 100,同时 θ 和 θ 保持为 0。当θ值设置在{200, 300, ..., 600}范围时,模型性能明显下降,这与RAG任务中的观察结果相吻合。θ主要调节示例段对模型的影响。对于SST2任务(即对评论情感进行分类),由于LLM可能已具备相关基础知识,选择θ可以适度降低示例段的影响。而对于TREC任务(需LLM从示例中学习问题类型),保持θ则更为合适。结论本文提出了一种创新方法——位置工程,通过微调提示中的位置信息,显著提升了任务表现。在多种任务和模型上的实验均验证了其有效性。
与需在复杂文本空间进行搜索的提示工程相比,位置工程更易于优化。更重要的是,位置工程仅涉及更新LLMs的输入位置索引,无需增加总体计算开销。
此外,位置工程与提示工程可以有机结合,共同发掘LLMs的潜在能力,使其性能得到充分发挥。有兴趣的同学可以沿着这个方向多研究研究。