NVIDIA Dynamo支持亚马逊云科技服务,提供高效推理规模

亚马逊云科技 (AWS) 开发者和解决方案架构师现在可以在基于 NVIDIA GPU 的 Amazon EC2 上使用 NVIDIA Dynamo,包括由 NVIDIA Blackwell 加速的 Amazon EC2 P6,并添加了对 Amazon Simple Storage (S3) 的支持,此外还有与 Amazon Elastic Kubernetes Services (EKS) 和 AWS Elastic Fabric Adapter (EFA) 的现有集成。此次更新将大规模部署大语言模型 (LLM) 的性能、可扩展性和成本效益提升到了新的水平。
NVIDIA Dynamo 扩展并服务于生成式 AI
NVIDIA Dynamo 是专为大规模分布式环境打造的开源推理服务框架。它支持所有主流推理框架,例如 PyTorch、SGLang、TensorRT-LLM 和 vLLM,并包含高级优化功能,例如:
这些功能使 NVIDIA Dynamo 能够为大规模多节点的 LLM 部署提供出色的推理性能和成本效益。
与亚马逊云科技服务无缝集成
对于在 AWS 云上部署 LLM 的 AWS 开发者和解决方案架构师,Dynamo 将无缝集成到您现有的推理架构中:
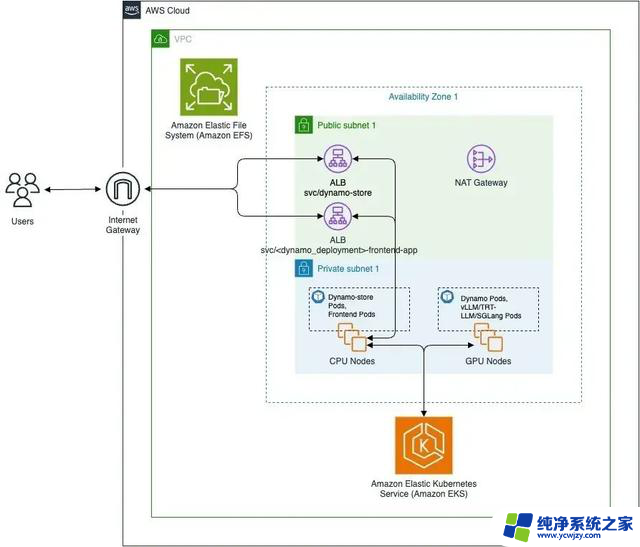
图 1:使用 Amazon EKS 的 AWS 部署架构上的 Dynamo
在 Blackwell 驱动的 Amazon P6 实例上
使用 Dynamo 优化推理
Dynamo 与任何 NVIDIA GPU 加速的亚马逊云科技实例兼容,但与由 Blackwell 提供支持的 Amazon EC2 P6 实例搭配使用时,可显著提升部署 DeepSeek R1 和最新 Llama 4 等高级逻辑推理模型时的性能。Dynamo 通过管理预填充和解码自动缩放以及速率匹配等关键任务,简化并自动处理分离 MoE 模型的复杂部署流程。
同时,Amazon P6-B200 实例具有第五代 Tensor Core、FP4 加速和 2 倍于上一代的 NVIDIA NVLink 带宽,而由 NVIDIA 提供支持的 P6e-GB200 Ultra 服务器具有独特的扩展架构,可提供 130 TBps 的聚合全互联带宽,旨在加速混合专家模型 (MoE) 部署中广泛采用的专家并行解码操作所需的密集型通信模式。Dynamo 和 P6 驱动的 Blackwell 实例相结合,可提高 GPU 利用率,提高每美元的请求吞吐量,并推动生产级 AI 工作负载的利润可持续增长。
开始使用 NVIDIA Dynamo
深化 Dynamo 与亚马逊云科技的集成可帮助开发者无缝扩展其推理工作负载。
NVIDIA Dynamo 可在任何 NVIDIA GPU 加速的亚马逊云科技实例上运行。部署 NVIDIA Dynamo,即刻开始优化推理堆栈:
https://github.com/ai-dynamo/dynamo