祭出大模型用芯片,AMD剑指英伟达,致力于超越竞争对手

英伟达在三个月前发布了大模型专用芯片H100 NVL,作为GPU赛道上的老对手,AMD选择正面迎击。
经过一个多月的预热,6月14日凌晨,AMD如约在旧金山召开“AMD数据中心与人工智能技术首映会”,并在会上展示了其即将推出的AI处理器系列。
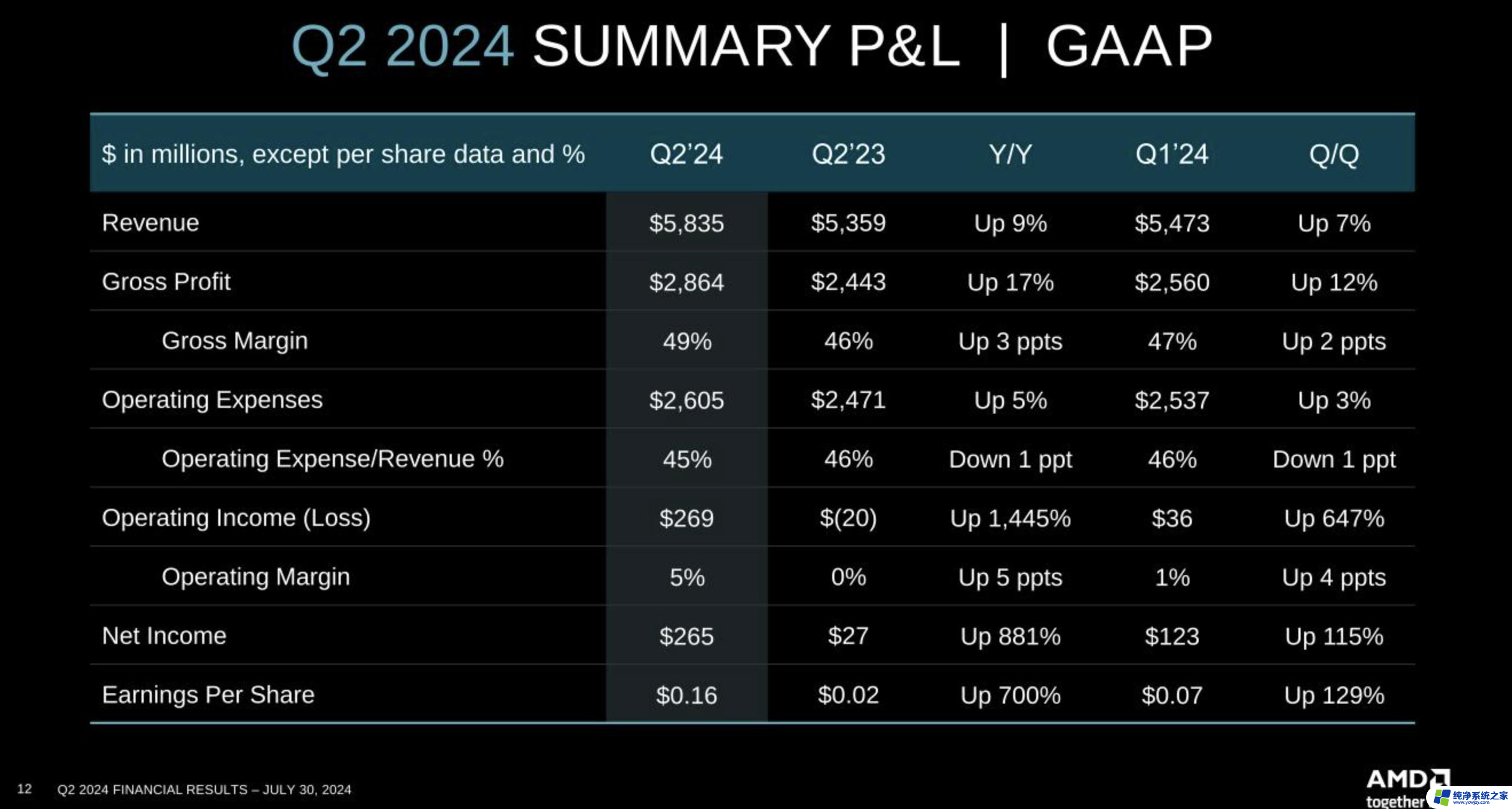
在首映会上,人称“苏妈”的AMD公司CEO苏姿丰。率先公布了MI300A,称这是全球首个为AI和HPC打造的APU加速卡,根据芯片参数,该APU加速卡拥有13个小芯片,总共包含1460亿个晶体管:24个Zen 4 CPU核心,1个CDNA 3图形引擎和128GB HBM3内存。
最值得关注的则是,AMD针对大语言模型发布的MI300A优化版本。据悉,MI300X内存达到了192GB,内存带宽为5.2TB/s,Infinity Fabric带宽为896GB/s,晶体管达到1530亿个。苏姿丰称,“你拥有的内存越多,该芯片可以处理的型号就越多。我们在客户工作负载中看到,它的运行速度要快得多。”
此外,MI300X提供的HBM密度是英伟达H100的2.4倍,HBM带宽是竞品的1.6倍。为了展示其性能,在现场演示中,苏姿丰用Hugging Face基于MI300X的大模型,实时写作了一首关于举办地旧金山的诗歌。
向来以“性价比”优势打开市场的AMD,这次似乎也不例外。MI300X过硬的参数,可以运行比英伟达H100更大的模型,苏姿丰还表示,生成式AI模型可能不再需要数目那么庞大的GPU,可为用户节省成本。
AMD称,MI300系列芯片将于第三季度开始批量生产,并将于第四季度开始量产。发布会上,苏姿丰并没有透露哪些公司将计划购买MI300X或MI300A。仅表示,MI300X主要客户将在第三季开始试用,MI300A,现在还在向客户推出。
另外,关于MI300系列芯片的成本,以及这款产品将如何提振营收等问题,AMD并没有提及。
不过,AMD此次却表现出极强的要硬刚英伟达的目标。此前,英伟达推出了带有8个 Nvidia H100或A100 GPU和640GB GPU内存的云计算机,AMD此次也发布了集合8个MI300X,可提供总计1.5TB的HBM3内存的“AMD Instinct Platform”。为了对标英伟达的CUDA,AMD表示公司也有自己的芯片软件“ROCm”。
在首映会上,AMD还对旗下第四代EPYC(霄龙)处理器家族进行了更新,推出了代号名为 Bergamo 的新产品,最高具有128核心、256线程。相较于现有的第四代 EPYC 处理器,Bergamo更着重于“商业层面的云计算”。其搭载了820亿个晶体管,并能够最高支持128个Zen 4c核心,兼容x86 ISA指令,可相对满足深度云计算的应用需求。
苏姿丰表示,Bergamo处理器可提供AMD目前最大的vCPU运算密度,相比于AMD此前的EPYC处理器,Bergamo 处理器可最高提升2.7倍能源效率,并提供三倍容器数量。
不过,AMD的这场发布会并没有让其在资本市场受益。在发布会前,AMD今年股价已经增长1倍,但在发布会后,AMD的当日股价收盘却下跌了3.6%,反而英伟达股价收盘则上涨3.9%。
同处这场AI浪潮,AMD与英伟达均进行了大手笔投入,AMD为何难让投资者增长信心呢?在GPU市场,苏姿丰接手后的AMD被视为英伟达的最强竞争对手,但在人工智能计算领域,英伟达占据着主导地位。
英伟达三个月前发布的H100在大模型爆发导致的算力紧缺背景下,由于市场上几乎没有可规模替代的方案。包括微软、谷歌、特斯拉、Facebook、华为、阿里、腾讯、字节跳动、百度等在内的企业,均利用英伟达GPU芯片组建AI计算集群,因此,包括H100在内的AI算力芯片被抢至断货,H100甚至一度被炒作到4万美金。
AMD正面与英伟达竞争,但英伟达已在AI训练端先后推出了V100、A100、H100三款芯片,并且向中国大陆销售了A100和H100的带宽缩减版产品A800和H800。AMD此次发布的GPU产品在硬件性能参数上超越英伟达,但在算力紧缺的背景下未能向市场及时供应产品,相较于英伟达已经迟了一步。
本文源自AI星球