高通、AMD芯片大厂争相发布跑一万参数大模型服务器,下注NPU,智涌要闻
编辑丨苏建勋
为期三天的2024年台北电脑展(Computex 2024),6月7日已落下帷幕。在这一次的展会上,AI成为贯穿一切的主题。英伟达、AMD、英特尔、高通等芯片大厂的话事人们纷纷做了主题演讲,也让这次展会的参与人数比上一届暴涨了 80%。
除了用主题演讲表明对于未来AI的立场之外,各大芯片大厂或秀出了自己的新产品,或公布了未来的产品路线图。而这些公司在展会上的一举一动,也刺激着他们的股价表现。
在台北电脑展举办之前,芯片大厂们的股价已经有了不同程度的提振;而在为期三天的展会期间,AMD、英伟达的股价双双增长了4%左右,高通的股价也有 3%的提升,Arm更是有10%的股价提升。
在Computex 2024上,各大芯片大厂在“斗”什么?背后又蕴藏着各家什么思考?这又将如何影响未来的行业走势?

Computex 2024
AMD:迎战英伟达,CPU+NPU+GPU多面下注相比于英特尔在GPU产品线上的“保守”,AMD这次在Computex上显得相当激进,策略是在CPU、NPU、GPU方面同时下注。
比如,在AI服务器芯片领域,此次AMD发布了重磅的Instinct MI325X,并且计划在2024年四季度上市。AMD还直接把英伟达不久前发布的H200拉出来对标,在最关键的性能、内存、带宽等参数上全面发起进攻。
根据介绍,相比英伟达H200,AMDInstinct MI325X的计算性能是其1.3倍、内存容量是其2倍、带宽是其1.3倍。
能够跑多大的模型,也是当下这些先进GPU面临市场考核时的一大考核标准。据AMD方面介绍, 一台搭载着AMDInstinct MI325X的八卡服务器,最多可以跑一万参数的大模型,是同等条件下英伟达H200服务器的双倍。
在此次展会上,AMD创始人苏姿丰也首次罕见明确了未来AMD在GPU上的产品节奏——每年都会迭代一款新的产品,2024年年底是AMDInstinct MI325X,2025 年将发布Instinct MI350X系列。
而值得注意的是,在不久前英伟达的财报会议上、以及此次的展会上,英伟达黄仁勋也都恰好也提及了,在 Blackwell芯片之后,英伟达也将保持一年一迭代的产品节奏。双方火药味颇浓。

lisa su发布Instinct MI325X
这也不难理解,AMD MI系列的芯片未来是支撑起他们营收的一大关键点。根据AMD方面此前乐观预计,在2024年年底,数据中心GPU将给AMD带来高达20 亿美元的收入。苏姿丰此前也暗示,这颗芯片得到了行业的广泛关注和好评。
在此次Computex上,AMD除了抓住数据中心的机会,另一手还抓住了AI PC在端侧的机遇,发布了两款王炸产品。
此次,他们发布了AMD Zen 5架构的锐龙9000系列桌面处理器,这颗处理器被AMD方面自封为“地表最强消费级CPU”。
由于基础架构的升级,这颗处理器的性能有了大幅度提升。AMD官方专门把英特尔的酷睿 i9-14900K拉出来做了对比。AMD的这颗芯片在游戏场景中的速度快了 4%-23%,测试速度快了 7%-56%。
这次,AMD还秀了他们的朋友圈,惠普、微软、联想等PC厂商都即将推出搭载这颗芯片的笔记本产品。
去年以来,为了加强AI PC在端侧的计算能力,AMD还尝试开辟出独立的NPU产品,集成到他们的CPU上——早在去年,AMD发布了首颗集成了NPU的 X86处理器(锐龙 7040系列)。
但在此次展会上,AMD的NPU的计算能力有了超强升级。据AMD方面介绍,AMD锐龙AI 300系列上搭载的NPU,可以提供超过 50TOPS的AI算力——纸面上是上一代产品的5倍。
一边迎战英伟达,一边掣肘英特尔,是AMD如今的双线策略。
英伟达:画了饼,但股价炸了这次Computex上,英伟达不像英特尔、AMD一般发布新产品,黄仁勋的演讲基本是重新介绍了他们不久前在GTC上的产品和服务细节(包括NIM微服务、AI工厂等等)。
“炒冷饭”之余,黄仁勋也透露出了更重要的信息点。公布了他们产品未来的规划——
据他介绍,英伟达将在2025年推出Blackwell芯片的迭代版本,Blackwell Ultra AI芯片,并在2026年更新下一代全新架构Rubin,在2027年推出基于这一全新架构的升级版Rubin Ultra。
黄仁勋还稍微透露了全新架构Rubin的结构:全新的GPU、新的基于Arm架构的CPU、配备NVLink 6、融合InfiniBand或以太网交换机的先进网络。
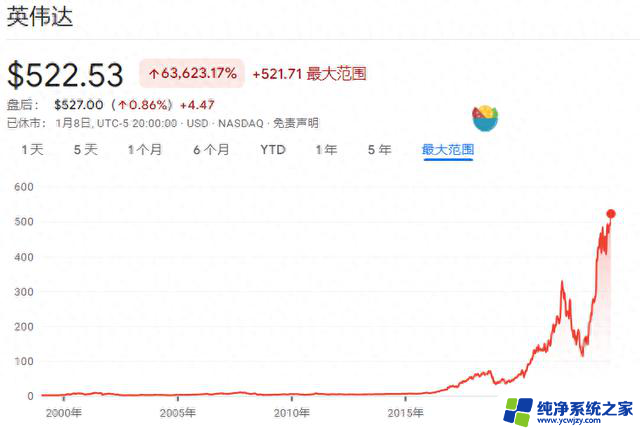
这也意味着,英伟达将会继续在高算力这一条路上蒙眼狂奔。而股价也给予了相应的反馈。在展会期间,英伟达的股价冲上了三万亿美元的大关,超越了苹果,仅次于微软。而英伟达股价飙升也堪称火箭速度,值得注意的是,在一年前,英伟达的股价还没有超过1万亿美元。
英特尔:巩固数据中心市场,开发存量在过去,随着AI大模型的普及千行百业,数据中心的一大趋势是出现多元化算力,GPU逐渐称为AI服务器的一项关键部件——一般情况下,一个AI服务器的芯片配置一般是1-2个CPU,再搭配8块的GPU。
与此同时,AI服务器在数据中心的依旧保持高增长态势,IDC此前数据显示,2023年中国加速服务器市场中,GPU服务器占据了九成市场。这一市场趋势之下,GPU的增长势头远远盖过了CPU。
英特尔虽然也在布局GPU的产品,但主力还是放在巩固他们在CPU的传统优势,开发服务器的存量市场。
这其实也不难理解,一位行业人士告诉《智能涌现》,由于GPU服务器的价格太高,目前对于一些数据量不大的模型,行业中也在尝试用表现更好的CPU来覆盖一部分AI计算任务。
此次,英特尔发布了他们的新一代数据中心芯片「至强6」。

英特尔至强 6
「至强 6」分为两个版本:性能核(E核)和能效核(P核),分别侧重高性能和低能耗,让用户根据实际使用诉求取用。这颗芯片是基于英特尔的 Intel 3制程工艺生产而成。
有“电老虎”之称的数据中心,能耗一直是行业在持续攻坚的难题,这正是此次「至强 6」的一大卖点。据英特尔方面介绍,和上一代产品第五代至强处理器相比,「至强 6」的功效能耗比大大提升——最高可以节省280w功耗,四年的时间,能够减排二氧化碳34kmt。
为了开发存量市场,这次「至强 6」也能带来更强大的服务器机架整合能力,帮助老客户进行老服务器产品的升级。比如,此前使用英特尔第二代至强可扩展芯片需要200个机架,但「至强6」只需要66个,机架整合率3:1。
这意味着,数据中心可以节省更多空间的同时,还能进一步获得更高的算力。据英特尔方面介绍,相比于此前的服务器芯片,「至强 6」最多有4.2 倍的性能提升。
在GPU产品上,不久前英特尔已经发布了Gaudi3,但在此次Computex上,英特尔虽然没有公布太多产品进展,但英特尔CEO基辛格还是在演讲中暗搓搓提示——他们的Gaudi3,未来会比竞争对手更便宜。

英特尔CEO基辛格
高通和微软:“Copilot+PC”从概念走向现实不久前,微软在开发者大会上提出了AI PC的新概念”Copilot+PC“。而在此次 Computex上,这也成为了行业一大关注热点。
值得注意的是,引领移动生态的芯片大厂高通,这次也不愿意放过AI PC的机遇,和微软有了合作绑定,Copilot+PC全面搭载了高通的NPU——骁龙X系列平台。
所谓的“Copilot+PC,微软是在电脑系统内置了40多个AI小模型,让笔记本也能够支持多元的AI能力。
比如,AI PC可以根据邮件等信息,对你的行程安排提出建议;或者AI也可以为你提供主动服务,比如根据摄像头识别到你的状态,帮你提供对应的建议,或者是帮你和网站的客服沟通等等。
而为了满足AI端侧计算的需求,微软还和高通对Copilot+PC下了定义,起草了具体的参数标准——比如,电脑的NPU需具备40TOPS以上的算力、配备至少16GB的内存、和256GB的SSD。此外,电脑还要有更长的的电池续航时间。
在AI PC上,算力上的一项趋势是,AI负载有逐渐从CPU、GPU,下放到NPU上。根据高通方面介绍,高通的NPU特点正是兼顾了低功耗和高性能——骁龙XElite NPU的每瓦特性能,是苹果M3芯片的2.6倍,是英特尔酷睿Ultra7处理器的5.4倍。
高通这颗NPU在AI PC上的落地速度也很快。在Computex上,华硕、宏碁、戴尔、联想、惠普等厂商都官宣了和高通的合作,微软的“Copilot+PC”概念正走向现实,快速复制到多个厂商上,而高通也顺势扩充自己在PC行业的地位。
Arm:披露AI进展,但还是很审慎一直以来,Arm在AI上的布局可谓相当谨慎,或者可以说是有些缓慢。在这次Computex上,Arm终于有所行动。此次,Arm推出基于人工智能优化的Arm终端计算子系统 (CSS) 、以及相对应的Arm Kleidi软件系统。

Arm 终端事业部产品管理副总裁 James McNiven
Arm终端计算子系统 (CSS) 包括这些成分:Arm最新的Armv9 CPU、Arm Immortalis GPU、以及最新的CoreLink系统互连、系统内存管理单元 (SMMU)。这些都将基于3纳米工艺生产,这也是迄今速度最快的Arm计算平台。
看起来有点复杂,可以这么理解Arm这次的产品思路——过去Arm是芯片厂商的上游,提供的是芯片IP,但在AI时代下,下游的终端厂商希望能够更快推出产品,产业链需要更加集成化,而Arm也顺应了这一速求。Arm终端计算子系统 (CSS) 的推出,意味着Arm往前走了一步,提供了更加集成的IP方案,缩短下游产品的上市进程。
不过,Arm对于人工智能的态度依旧审慎。尽管目前市面上几乎所有的手机芯片都是基于Arm架构打造,但端侧AI算力都是用各家自己的NPU来应对。
在一次公开采访中,Arm 终端事业部产品管理副总裁 James McNiven回复《智能涌现》在内的媒体称,不会专门做一个Arm的NPU产品线,支持手机厂商们的自由选择空间。
end